30. ceilometer api扩展与horizon前后端交互流程解析¶
高安云开发在基于ceilometer项目基础中,进行监测项扩展。 目前,绝大部分监测项扩展已经完成,下一步很重要的工作,就是对扩展监测项, 编写对应的client,以方便前端开发者调用获取展示数据。 因此,这篇文章,一方面会简要提及ceilometer-api扩展步骤, 也会对horizon调用相关api—>ceilometerclient—>ceilomter-api的完整流程进行分析, 同时会把开发过程中,所遇到的坑罗列出来,供大家参考和一起讨论。
30.1. ceilometer-api扩展¶
ceilometer-api是一个http服务,是ceilometer所有服务总入口。有关ceilometer-api扩展, 杰哥之前写过详细的文档,也可以参考pecan官方文档。这里不在赘述。
编写了ceilometer-api扩展后,重启rest-api服务,然后通过curl命令行进行测试。比如, 我编写的rabbit相关监测项,测试如下:
root@allinone-v2:/# token_id=`/smbshare/get_token.sh`
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3503 100 3401 100 102 9104 273 --:--:-- --:--:-- --:--:-- 9142
root@allinone-v2:/#
root@allinone-v2:/#
root@allinone-v2:/# curl -H "X-Auth-Token: $token_id" http://localhost:8777/v2/rabbit/users
[{"tags": "administrator", "name": "guest", "password_hash": "XBYJBalVMFOHwViSaL8U4wKv0Kg="}]root@allinone-v2:/#
root@allinone-v2:/# curl -H "X-Auth-Token: $token_id" http://localhost:8777/v2/rabbit/overview
{"node": "rabbit@allinone-v2", "management_version": "3.2.4", "queue_totals": {"messages_details": {"rate": 0.0}, "messages": 1, "messages_ready": 1, "messages_ready_details": {"rate": 0.0}, "messages_unacknowledged": 0, "messages_unacknowledged_details": {"rate": 0.0}}, }
root@allinone-v2:/#
30.2. ceilometerclient扩展¶
完成上一步的工作,下一步,就是编写ceilometerclient,可以参考官网ceilometerclient的使用文档, 然后进行仿写。下面以rabbitmq监测项为例,简要概括下步骤。
>>> import ceilometerclient.client
>>> cclient = ceilometerclient.client.get_client(VERSION, os_username=USERNAME, os_password=PASSWORD, os_tenant_name=PROJECT_NAME, os_auth_url=AUTH_URL)
>>> cclient.meters.list()
[<Meter ...>, ...]
>>> cclient.new_samples.list()
[<Sample ...>, ...]
这里VERSION版本号一般是2,下面是ceilometerclient的代码结构。
root@allinone-v2:/usr/lib/python2.7/dist-packages/ceilometerclient# ls
client.py client.pyc common exc.py exc.pyc __init__.py __init__.pyc openstack shell.py shell.pyc tests v1 v2
root@allinone-v2:/usr/lib/python2.7/dist-packages/ceilometerclient#
root@allinone-v2:/usr/lib/python2.7/dist-packages/ceilometerclient# ls v2
alarms.py events.py __init__.py meters.py query.py resources.py shell.py trait_descriptions.py
alarms.pyc events.pyc __init__.pyc meters.pyc query.pyc resources.pyc shell.pyc trait_descriptions.pyc
client.py event_types.py logs.py options.py rabbit.py samples.py statistics.py traits.py
client.pyc event_types.pyc logs.pyc options.pyc rabbit.pyc samples.pyc statistics.pyc traits.pyc
然后在v2目录下,新建rabbit.py文件,代码如下:
v2/rabbit.py
from ceilometerclient.common import base
from ceilometerclient.v2 import options
class Rabbit(base.Resource):
def __repr__(self):
return "<Rabbitmq record -- %s>" % self._info
class RabbitManager(base.Manager):
resource_class = Rabbit
def list(self, q=None):
path = '/v2/rabbit/%s'%q
return self._list(path)
并在v2/client.py中加入下面这行代码:
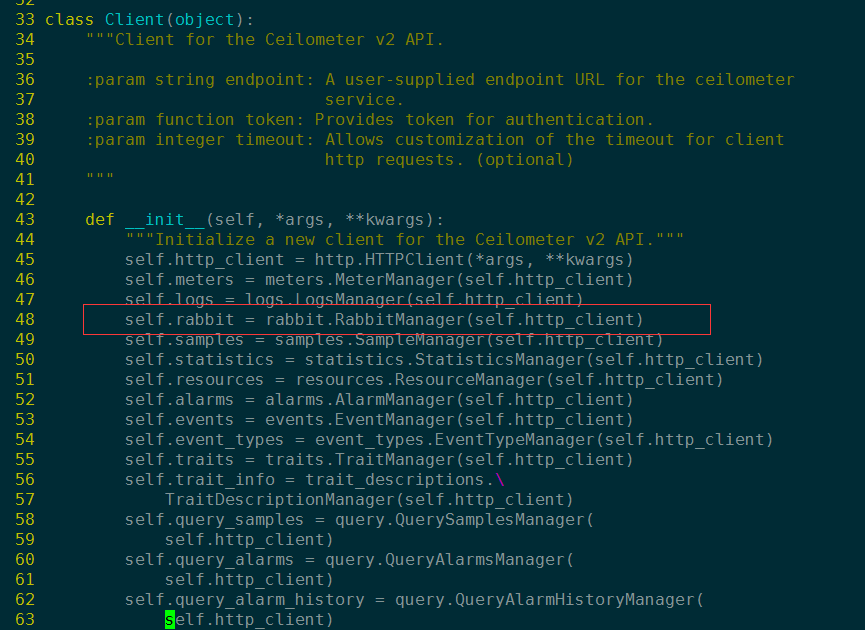
v2/client.py
简单测试下,看看能否取到数据:
cclient = client.get_client('2',
os_username='chensq',
os_password='cec123',
os_tenant_name='csq',
os_auth_url="http://10.10.10.10:5000/v2.0/")
print cclient.rabbit.list("users")
Error
在上面的测试中,结果提示异常。刚开始怀疑,是不是在编写client过程中, URL构造有问题,把上述代码单步执行调试,并通过查看ceilometer-api日志, 发现URL构造并没有问题。问题出在数据返回格式上。
ceilometer-api返回json格式数据,不要直接json.dumps对数据进行序列化,而要使用expose(‘json’)进行包装。 假如直接使用json.dumps,在上面的测试中结果总是会返回406错误(“No Acceptable”)。 暂时还没有定位到这两种方式,有什么区别。
class SystemLogController(rest.RestController):
@pecan.expose('json')
#@pecan.expose()
def get(self):
if pecan.request.GET.get('q.field', None) == 'page':
page = pecan.request.GET.get('q.value', 1)
else:
page = 1
page = int(page) if int(page)> 0 else 1
return utils.query_table(SystemLog, int(page))
def query_table(table, page=1):
# 优先查找前几条日志
#res = session.query(table).offset((page - 1) * LOG_NUM_PER_PAGE).limit(LOG_NUM_PER_PAGE)
#session.query(ObjectRes).order_by(ObjectRes.id.desc()).first()
# 优先查找后生成的日志
res = session.query(table).order_by(table.id.desc()).offset((page - 1) * LOG_NUM_PER_PAGE).limit(LOG_NUM_PER_PAGE)
# 直接json.dumps返回序列化日志,HTTP请求结果总是提示"No Acceptable",
# 直接直接返回对象,然后使用expose('json')包装,结果正常。
#return json.dumps([{"id": i.id,
# "desc": i.description.encode("utf-8"),
# "time": i.time.strftime("%Y-%m-%d %H:%M:%S")
# if i.time else datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# }
# for i in res
# ])
#
return [{"id": i.id,
#"desc": i.description.encode("utf-8"),
"desc": i.description,
"time": i.time.strftime("%Y-%m-%d %H:%M:%S")
if i.time else datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
for i in res]
另外,需要注意的是,也许我们可能会以为,编写ceilometerclient无非是通过Python相关http库, 封装并发送http请求,然后获取响应结果。刚开始,我也是这么想,并觉得ceilometerclient那一套, 是不是搞得太复杂。实际上这么做是有必要的,比如,ceilometerclient对http响应的处理上, 假如返回数据量太大,会通过生成器,多次读取获取响应结果;同时,还会针对不同类型数据, 作格式化处理,从而提高可用性、代码健壮性。值得大家借鉴和阅读!
测试运行结果:
root@allinone-v2:/# python /smbshare/test_cc1.py
============== list rabbitmq overview
[<Rabbitmq record -- {u'node': u'rabbit@allinone-v2', u'management_version': u'3.2.4', u'queue_totals': {u'messages_details': {u'rate': 0.0}, u'messages': 1, u'messages_ready': 1, u'messages_ready_details': {u'rate': 0.0}, u'messages_unacknowledged': 0, u'messages_unacknowledged_details': {u'rate': 0.0}},
u'contexts': [{u'node': u'rabbit@allinone-v2', u'path': u'/', u'description': u'RabbitMQ Management', u'port': 15672}, {u'node': u'rabbit@allinone-v2', u'path': u'/', u'port': 55672, u'ignore_in_use': True, u'description': u'Redirect to port 15672'}],
u'object_totals': {u'connections': 50, u'channels': 50, u'queues': 78, u'consumers': 142, u'exchanges': 50},
u'erlang_version': u'R16B03', u'listeners': [{u'node': u'rabbit@allinone-v2', u'protocol': u'amqp', u'ip_address': u'::', u'port': 5672}],
u'rabbitmq_version': u'3.2.4', u'message_stats': {u'publish_details': {u'rate': 0.6}, u'ack': 115024, u'deliver_get': 115024, u'deliver': 115024, u'publish': 115027, u'ack_details': {u'rate': 0.4}, u'deliver_details': {u'rate': 0.4}, u'deliver_get_details': {u'rate': 0.4}},
u'statistics_level': u'fine', u'statistics_db_node': u'rabbit@allinone-v2', u'exchange_types': [{u'enabled': True, u'name': u'topic', u'description': u'AMQP topic exchange, as per the AMQP specification'},
{u'enabled': True, u'name': u'fanout', u'description': u'AMQP fanout exchange, as per the AMQP specification'}, {u'enabled': True, u'name': u'direct', u'description': u'AMQP direct exchange, as per the AMQP specification'},
{u'enabled': True, u'name': u'headers', u'description': u'AMQP headers exchange, as per the AMQP specification'}], u'erlang_full_version': u'Erlang R16B03 (erts-5.10.4) [source] [64-bit] [smp:2:2] [async-threads:30] [kernel-poll:true]'}>]
30.3. horizon层封装¶
在上面的测试中,是直接通过硬编码用户名和密码进行认证的。而在OpenStack dashboards前端, 调用api获取OpenStack其他服务数据都是通过request中的用户token信息进行认证。并且, 在horizon项目中,与其他服务(如nova、neutron等)进行交互时,都会在horizon项目的根目录下, 有个专门的api目录,对其他服务提供的SDK client进行简单封装。
root@allinone-v2:/opt/cecgw/csmp/openstack_dashboard# tree api | grep -v pyc$
api
├── base.py
├── ceilometer.py
├── cinder.py
├── fwaas.py
├── glance.py
├── heat.py
├── __init__.py
├── keystone.py
├── lbaas.py
├── network_base.py
├── network.py
├── neutron.py
├── nova.py
在api/ceilometer.py文件中,有个如下所示的函数,是通过http请求用户token信息,获取client。
@memoized
def ceilometerclient(request):
"""Initialization of Ceilometer client."""
endpoint = base.url_for(request, 'metering')
insecure = getattr(settings, 'OPENSTACK_SSL_NO_VERIFY', False)
cacert = getattr(settings, 'OPENSTACK_SSL_CACERT', None)
LOG.debug('ceilometerclient connection created using token "%s" '
'and endpoint "%s"' % (request.user.token.id, endpoint))
return ceilometer_client.Client('2', endpoint,
token=(lambda: request.user.token.id),
insecure=insecure,
ca_file=cacert)
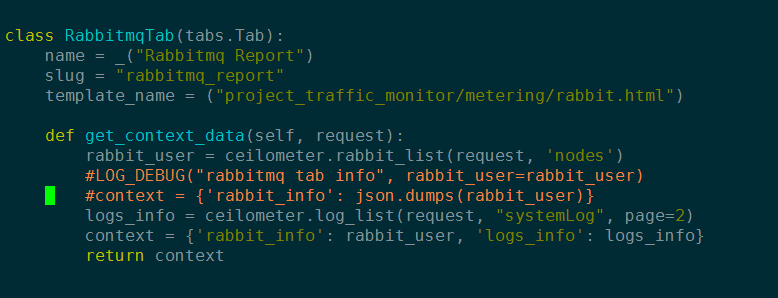
然后添加下列代码,简要封装获取rabbitmq监测项信息:
def rabbit_list(request, query=None):
#logs_record = ceilometerclient(request).logs.list(q=query)
rabbit_info = ceilometerclient(request).rabbit.list(query)
LOG_DEBUG(rabbit_info=rabbit_info)
return [str(s) for s in rabbit_info]
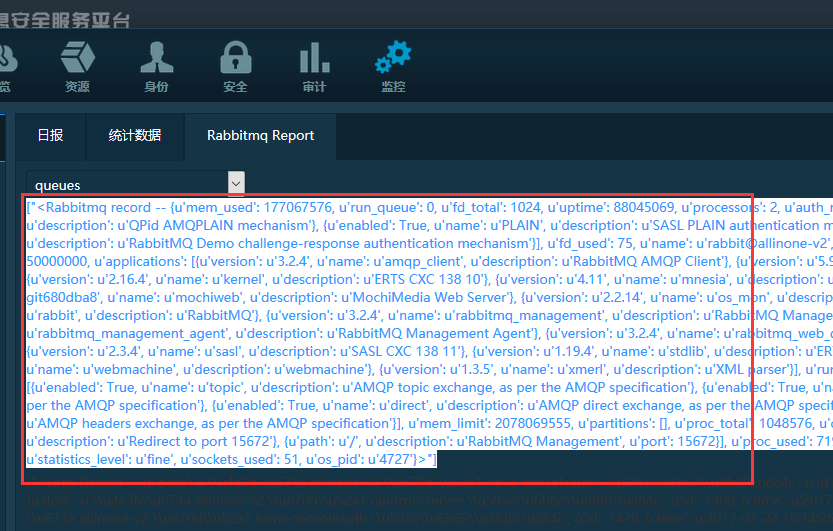
然后,在horizon前端,增加一个测试页面,看看整个流程下来,是否可以获取到rabbitmq监测数据。

重启apache2服务,刷新页面。数据显示出来了。